AI Model for Price Recommendation

AI has been injected as a key feature in several products handled by Investidea. In this article, we are sharing a full cycle of AI feature development for an e-commerce client who need Price recommendations for any product that they purchase and sell. This solution helps our client to standardize and automate the purchasing flow as well as increase profit on days-in-stock.
Context & methodology
Arguably the most mature Cross-industry standard process for data mining (CRISP-DM), is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model.
Team Data Science Process (TDSP) Life Cycle
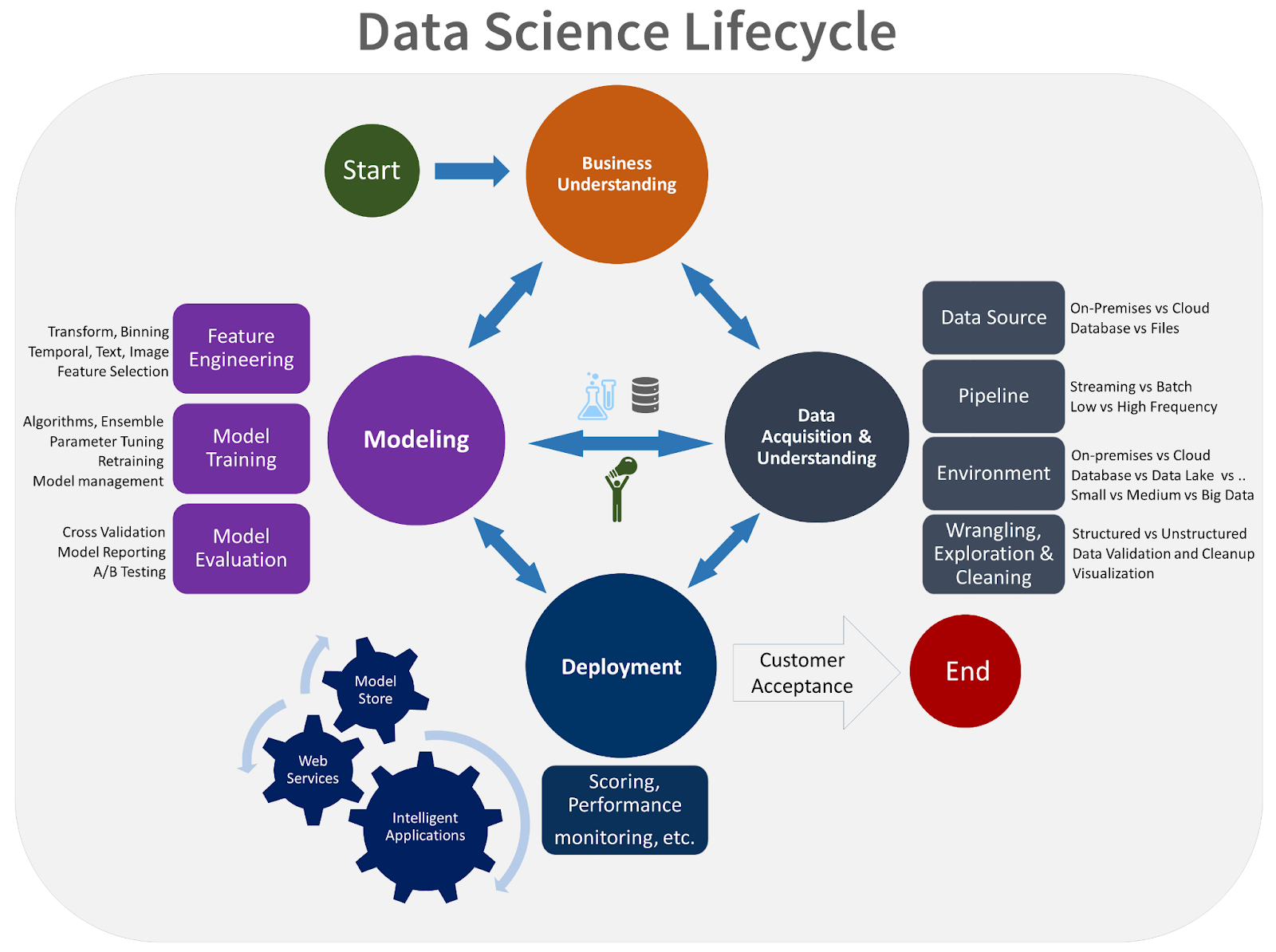
As this is mainly an exploratory data science project, we are mainly concerned with 3 major stages: Business Understanding, Data Acquisition and Understanding, and Modeling.
Business Understanding
- What business problems are we trying to address? Determine the selling price of a used motorbike in Indonesia.
- What data science solutions are we trying to build? A regression model to predict the selling price.
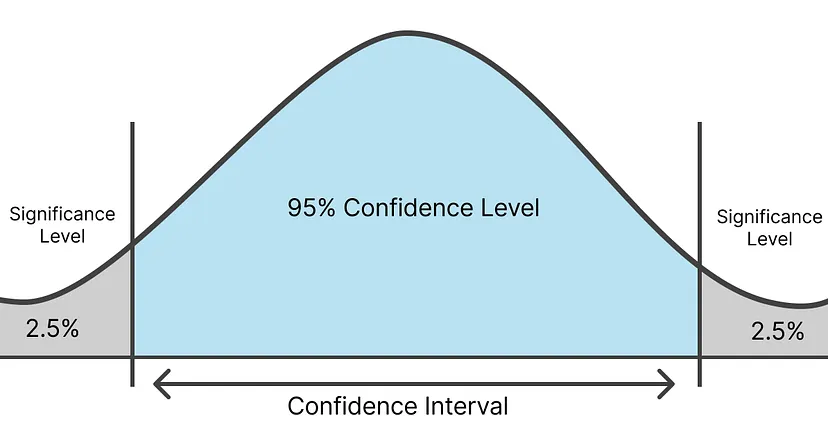
- What is the success metric? Meet a selling price prediction with the lowest Root Mean Squared Error (RMSE) possible with a confidence level of 95 percent by the end of a one-month project.
- What data do we expect? Raw data from the customer's Postgres database.
Data Acquisition and Understanding
- How do we ingest source data into the target analytic environment? Use SQL-dump method - extract the source database into a script file, then restore that database from the script file to a local server.
- How to do exploratory data analysis (EDA)?
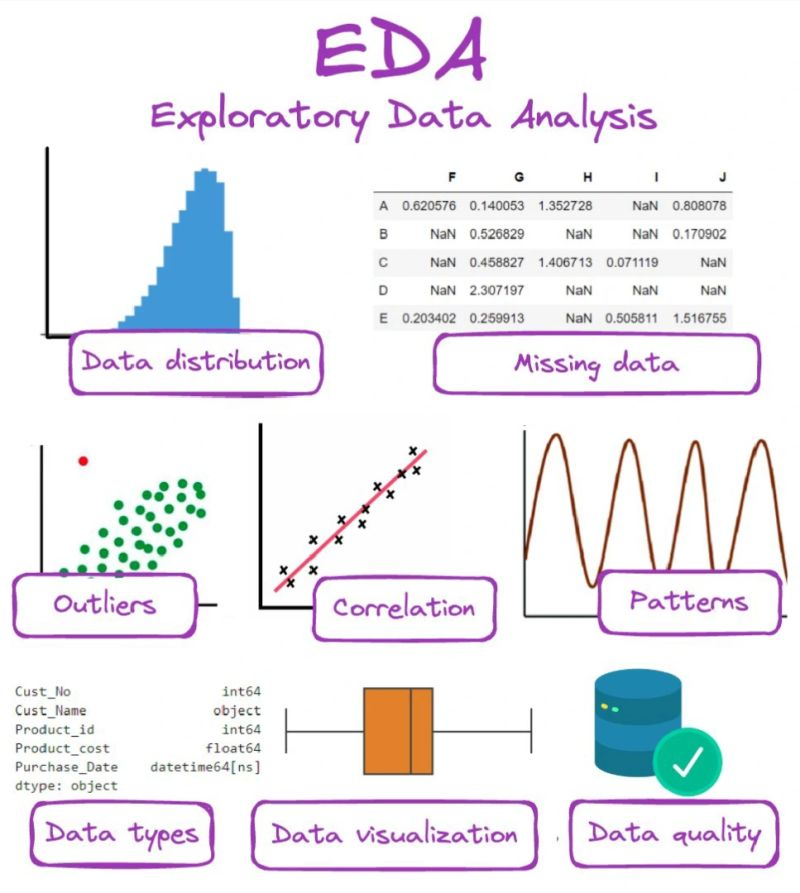
- Data attributes identification: Analyze and visualize data to understand its key characteristics, uncover patterns, and identify relationships between variables.
- Data preprocessing: Fill in missing values, detect, and remove noisy data and outliers.
Modeling
Feature engineering
We create appropriate features that help in improving the accuracy of the model. The features that are selected: Brand, Model, and Bike_age_month (how old a motorcycle is, from its manufacture time to now, in months). The target variable: Selling price.
Model training
Using the results from EDA, we split the clean dataset into two separate datasets:
- Records with selling price < 8000 IDR. For each Bike_age_month category: - Number of records must be at least 3. - Records must be in the (75%, 125%) range of its mean value; For all Bike_age_month categories: - Get at least 60 separate categories. We call this Low dataset.

- Records with selling price > 8000 IDR. For each Bike_age_month category: - Number of records must be at least 3. - Records must be in the (50%, 150%) range of its mean value; For all Bike_age_month categories: - Get at least 60 separate categories. We call this High dataset.

In the machine learning field, we use an algorithm that is run on a dataset to create a model. So for each Low/High dataset, in order to use a model for prediction, first we must decide on the algorithm that best satisfies the success metric. Next, we determine the confidence interval for the chosen algorithm. In the end, we create the final model from that algorithm.
Step 1: Choose the best algorithm
We will focus on supervised learning, and regression algorithms because we are trying to create regression models and we have fully labeled data. Four algorithms are chosen: Linear regression, Generalized linear model (GLM) - particularly Polynomial regression, Random Forest and Neural networks - particularly Multilayer perceptron (MLP).
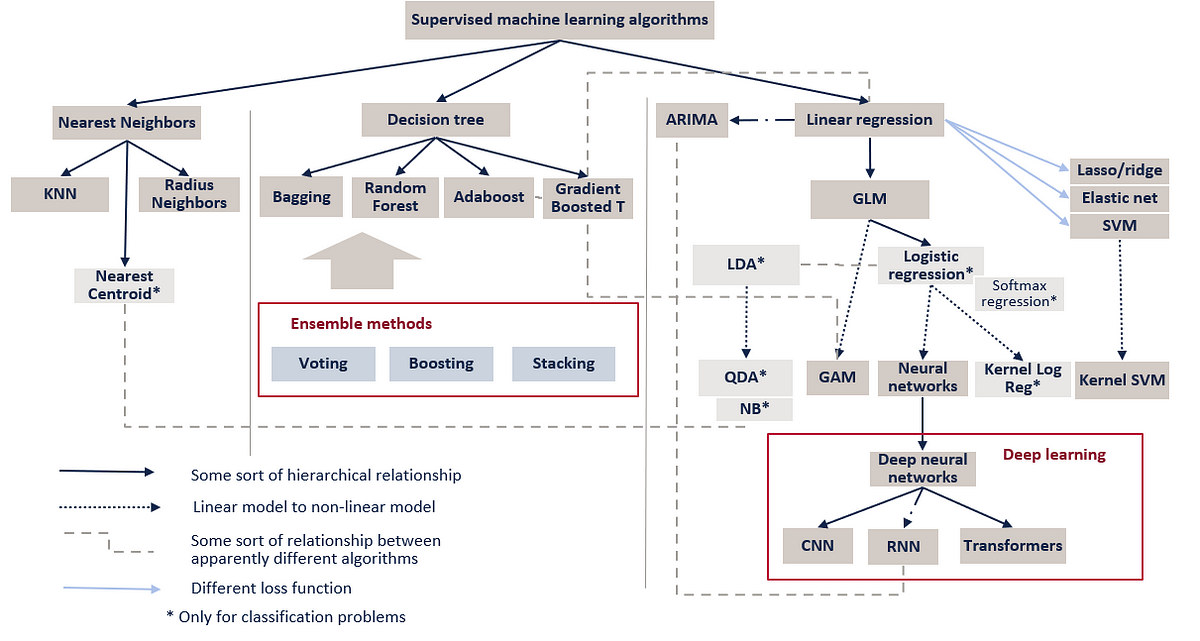
The method we use is described in detail:
- Split Low/High dataset into a training dataset (80% of data) and a test dataset (20% of data). In this step, we only use the training dataset.
- Apply k-fold cross-validation procedure on the training dataset for each chosen algorithm, with k=5.
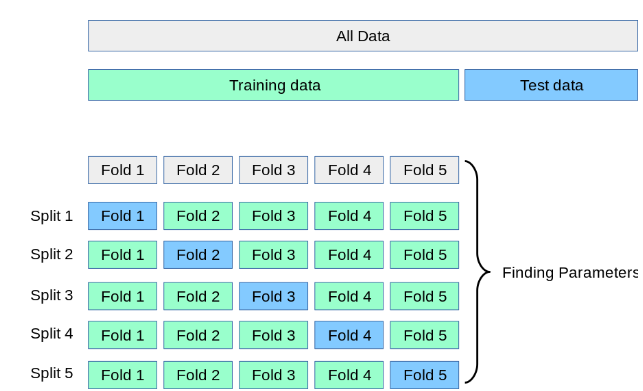
- Calculate the average negative RMSE of models from each chosen algorithm. The higher the score, the less error there will be, and hence, the better the algorithm.
- Compare the scores to determine the best algorithm.
By comparing the average score, we find that for both Low and High datasets, the Random forest algorithm performs better than all other algorithms.


Step 2: Get the confidence interval for the chosen algorithm
With our algorithm of choice being Random forest in both Low and High datasets, next we need to determine the range of RMSE of models created by the algorithm and the likelihood that the RMSE of a model from that same algorithm will fall between that range when making predictions on new data - i.e. the confidence interval for the chosen algorithm in each dataset. In our case, we opt for the 95% confidence level.
The method we use is described in detail:
- Bootstrap resampling the Low/High dataset a number of times = 100. For each iteration, a training dataset = the resampled dataset, limited in size to 50% of the original dataset, while a test dataset = records that are not included in the resampled dataset.
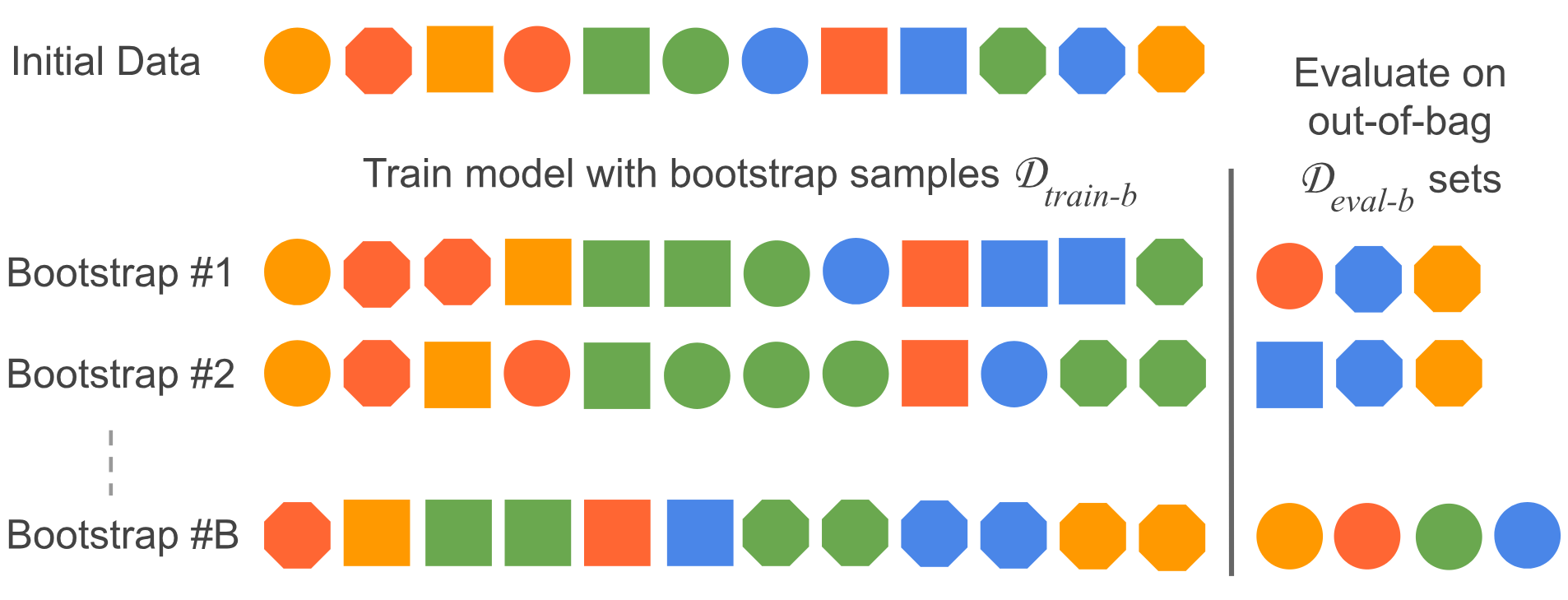
- Build a model and calculate the RMSE of the model in each iteration.
- Collect all RMSE values generated.
- Order the statistics, then select values at the chosen percentile for the confidence interval.
With the Low dataset, 95% confidence level of RMSE is between 527.6 and 528.7. With the High dataset, 95% confidence level of RMSE is between 1732.4 and 1739.8.
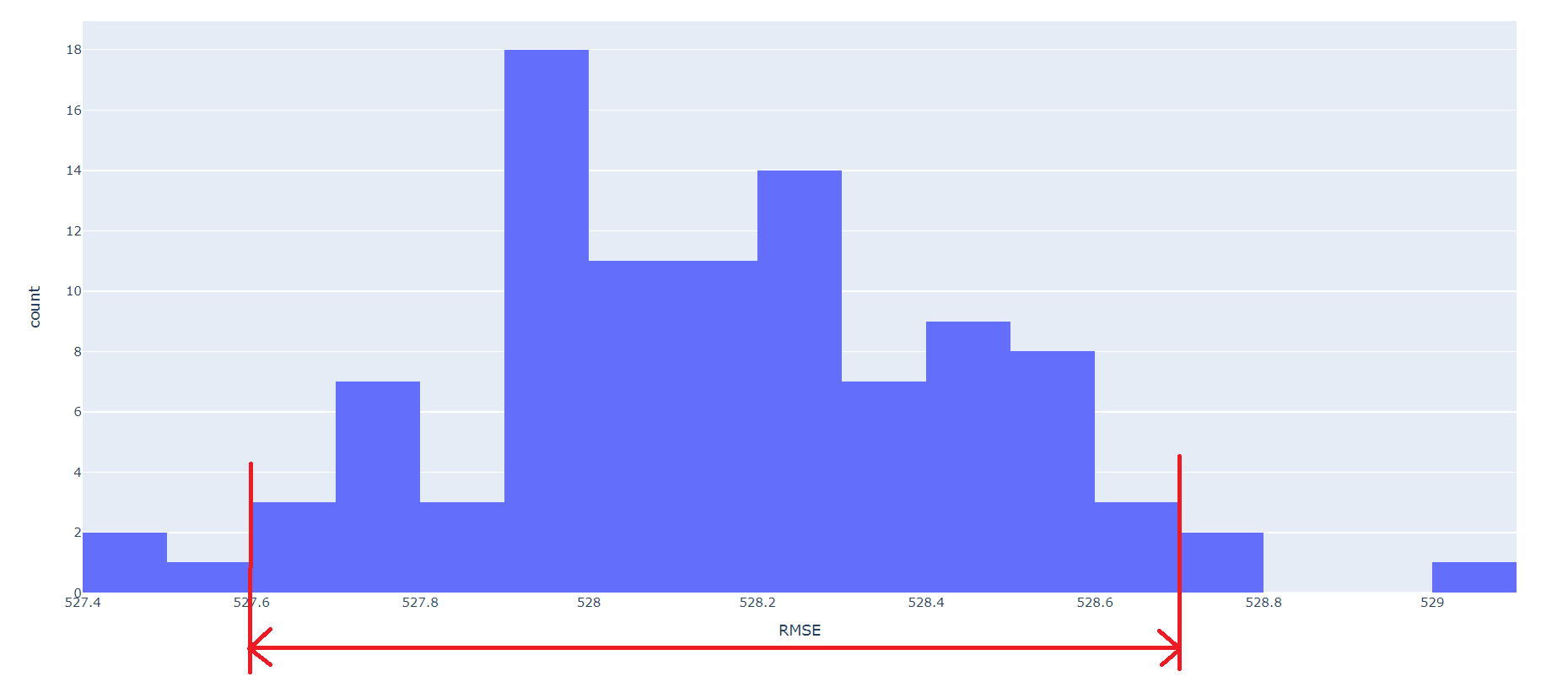
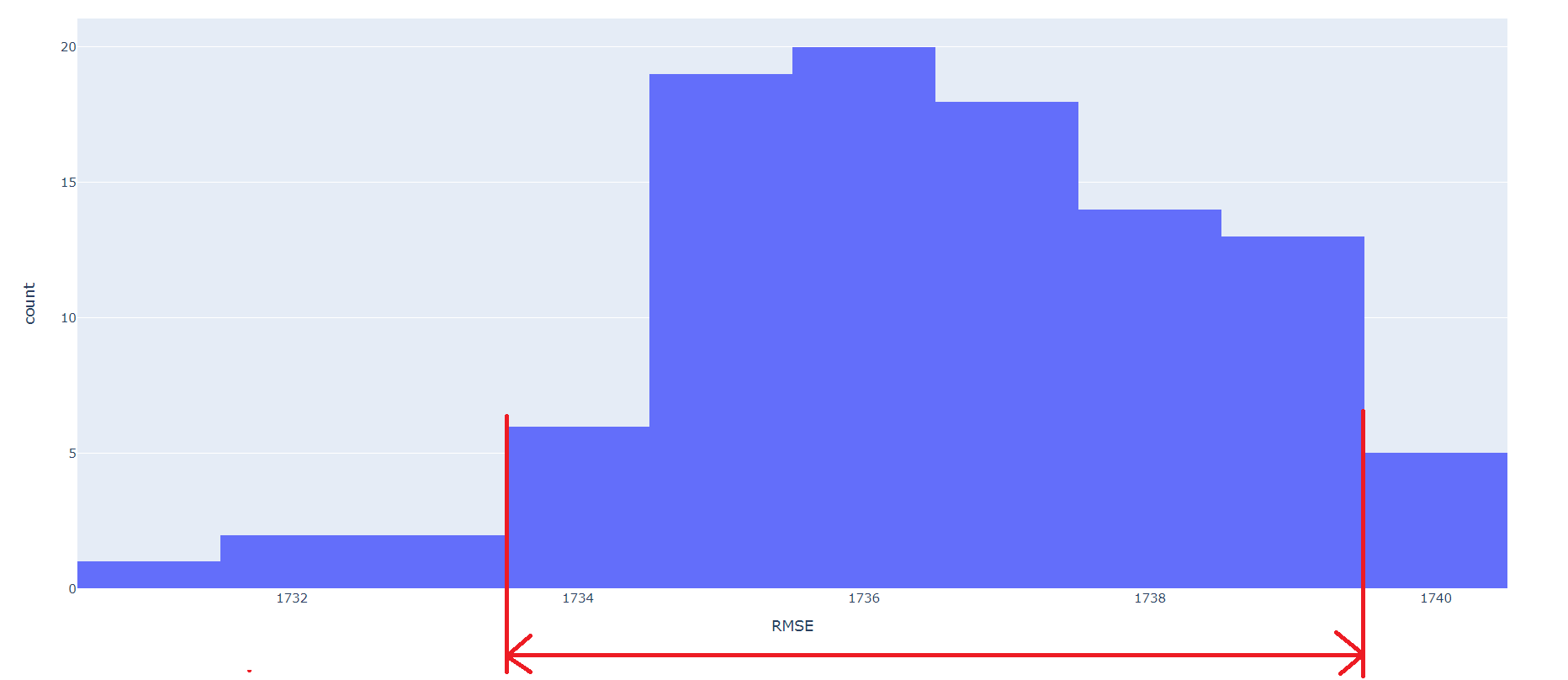
Step 3: Build the final model
With the best algorithm chosen and the confidence interval defined, we are now ready to build a model that we use to make predictions on new data - i.e. the final model.
The method we use is described in detail:
- For each Low/High dataset, a training dataset = all of the original dataset. There is no need for a test dataset in this step.
- We build a model from the chosen algorithm with the training dataset.
- Save the model.
Model evaluation
With the trained model now finally available to use, we need to determine if the model answers the business question with sufficient confidence given new data.
Here is an example question: We have a motorcycle with brand = Yamaha, Model = Y15zr, and Bike_age_month = 60. How much should we sell that bike for?
Answer from the model:
- If the bike is worth less than 8000 IDR with its age from 2 to 132 months, it should be sold for 6616 +/- (527, 528) IDR with 95% confidence level.
- If the bike is worth more than 8000 IDR with its age from 0 to 97 months, it should be sold for 9613 +/- (1732, 1740) IDR with 95% confidence level.
Conclusion
This approach helps us realize how revolutionary AI models are in solving real business problems in Price Recommendation. It also enables us to discover more about the potential of data and AI in applying to business success.
If you are running a digital product now or your team is using some internal digital product, there is always a room for applying AI into those products to support your business success. Please don't hesitate to contact us via hello@investidea.tech and share your business problem. We would love to discuss and support bringing AI into your product.

![[S1.07] AI Infrastructure as a Service](/blog/content/images/size/w720/2024/07/S1.-05--1-.png)
![[S1.06] AI Platform as a Service](/blog/content/images/size/w720/2024/07/S1.-05.png)
Comments ()