MongoDB aggregation framework stages and pipelining

Introduction
Fetching data in MongoDB may sometimes become tedious with CRUD find operation. For instance, you may want to fetch some embedded documents in a given field but the find operation will always fetch the main document and then it will be upon you to filter this data and select a field with all the embedded documents, scan through it to get ones that match your criteria.
Since there is no simple way to do this, you will be forced to use something like a loop to go through all these subdocuments until you get the matching results. However, what if you have a million embedded documents? You will unfortunately get frustrated with how long it will take. Besides, the process will take a lot of your server’s random memory and may terminate the process before you get all the documents you want, as the server document size may be surpassed.
In this article, we will deep dive into MongoDB’s Aggregation Framework and look into the different stages of the Aggregation Pipeline. We’ll see how we make use of these stages in an aggregation process. We’ll then look at the operators that can assist in the analysis process of input documents.
What is the Aggregation Framework?
The aggregation framework is essentially a pipeline-based system where documents pass through a sequence of stages, each stage representing a specific operation. Each stage in the pipeline takes input documents, processes them, and passes the results to the next stage. The output of the last stage is the final result of the aggregation.
Aggregation Pipeline
To scan the documents one by one in order to apply some operation to them will obviously outdo the purpose of the aggregation framework because it will consequently take much time to do this. Therefore, the data processing is done at the same time from different stages using the UNIX pipelining technique. Documents from a collection are channeled into a multistage pipeline from which they are converted into aggregated data.
We can show the aggregation process using a simple flow chart as below:

Aggregation Process
As we have discussed all these stages, we need to understand how to associate them in our querying process so that we get the desired results. The process starts with inputting documents from the selected collection into the first stages. These documents can pass through 1 or more stages with each stage involving different operations. A simple diagram of the pipeline process is shown below.

The output of each stage becomes the input of the next stage and any stage can be repeated to filter the documents further.
Basic Stages of Aggregation Pipeline
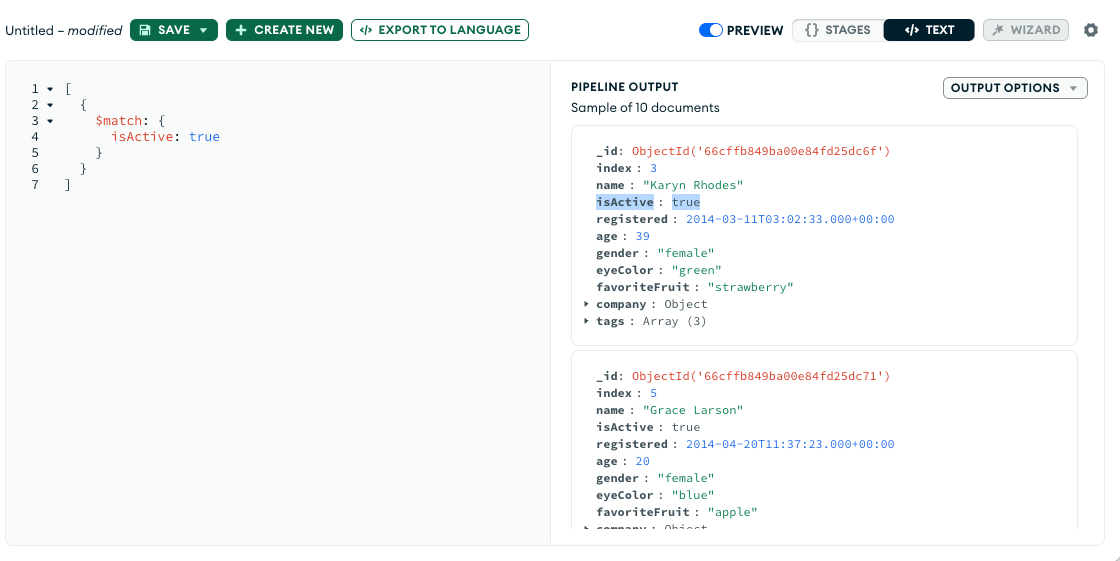
- $match: Filters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage.
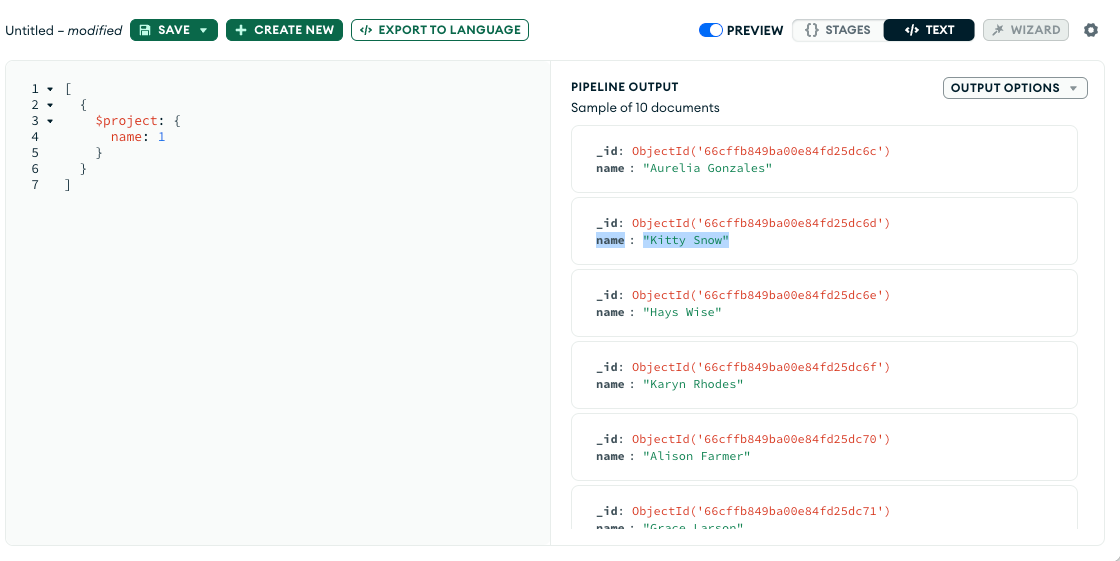
- $project: Passes along the documents with the requested fields to the next stage in the pipeline.
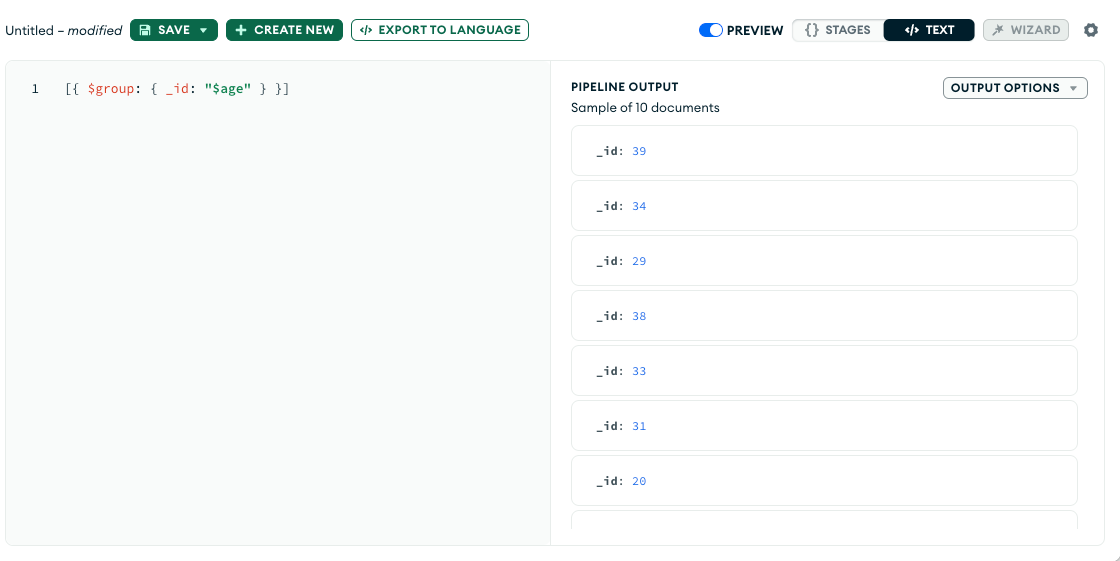
- $group: The
$groupstage separates documents into groups according to a "group key". The output is one document for each unique group key.
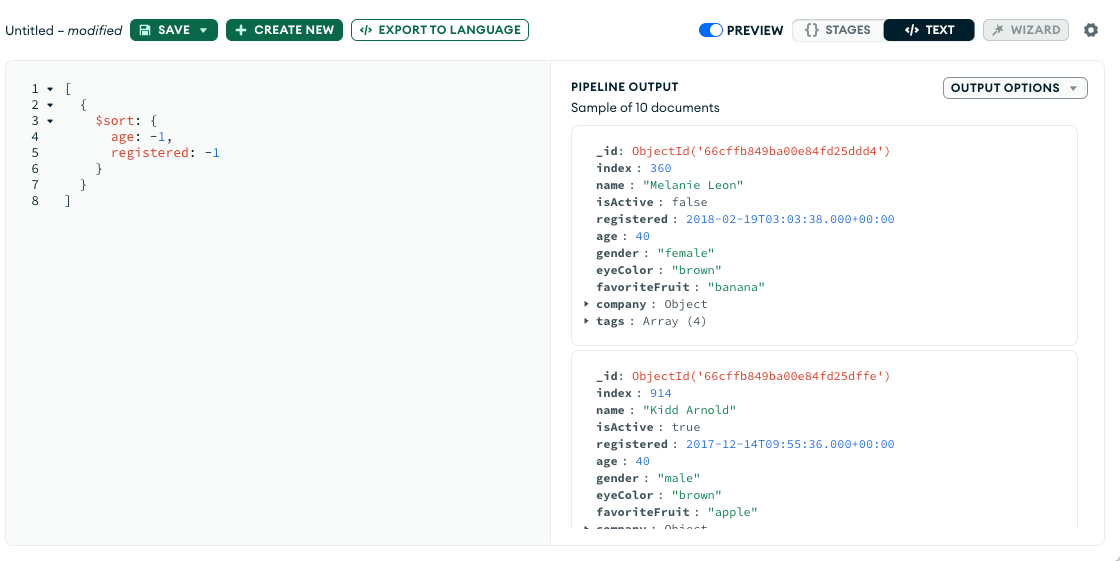
- $sort: Sorts all input documents and returns them to the pipeline in sorted order. For the field or fields to sort by, set the sort order to
1or-1to specify an ascending or descending sort respectively.
- $lookup: Performs a left outer join with another collection, combining documents from both collections based on a specified condition.
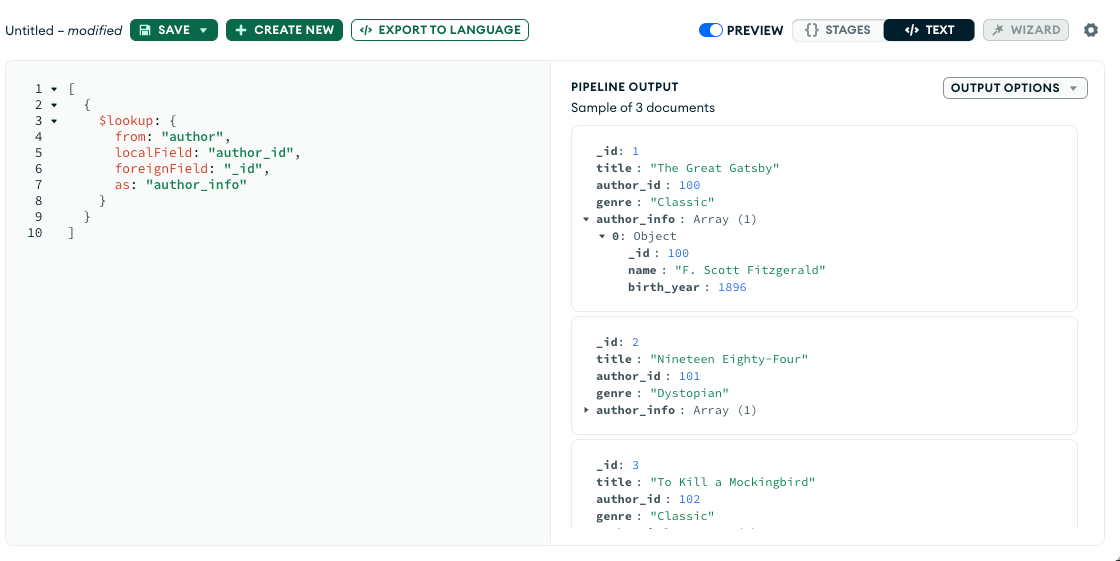
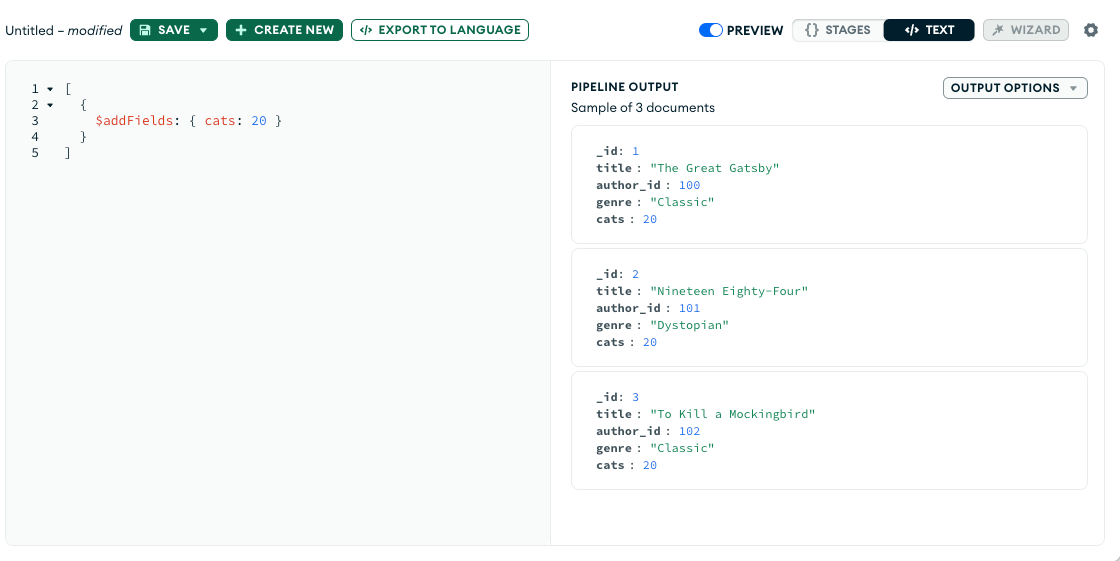
- $addFields: Adds new fields to documents.
$addFieldsoutputs documents that contain all existing fields from the input documents and newly added fields.
Set up the environment (Playground)
So we will see how aggregate pipeline works with some real-world examples. Follow step by step with me to fully understand the basic stages of the aggregation pipeline.
- Set up Docker Desktop
- Pull mongo
- Run and expose the port
- Install MongoDB Compass
- Insert Document
Here is the link to the sample document: https://gist.github.com/hiteshchoudhary/a80d86b50a5d9c591198a23d79e1e467
- Now we are ready to play!
Example
We will see how to example pipeline works with some real-world examples.
- How many users are active?
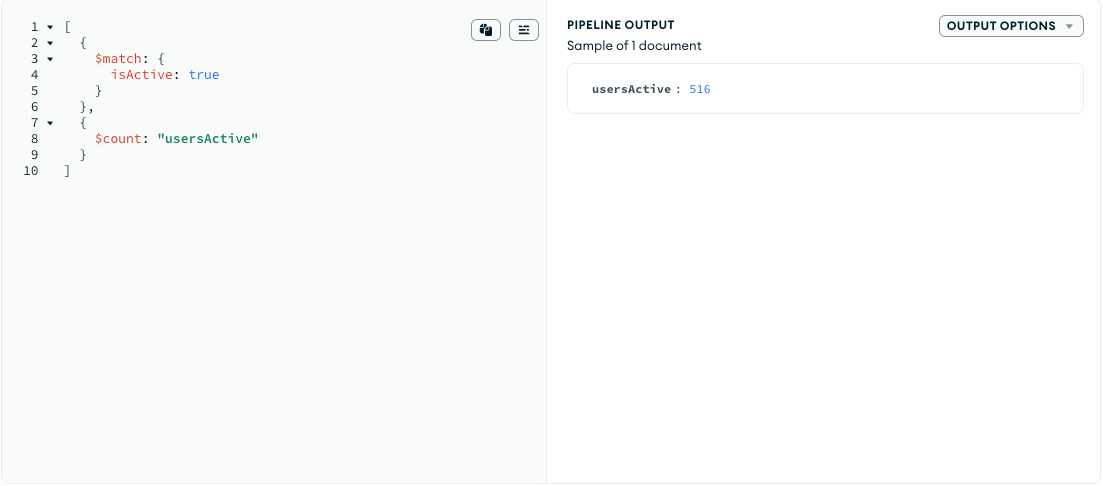
- What is the average age of all users?
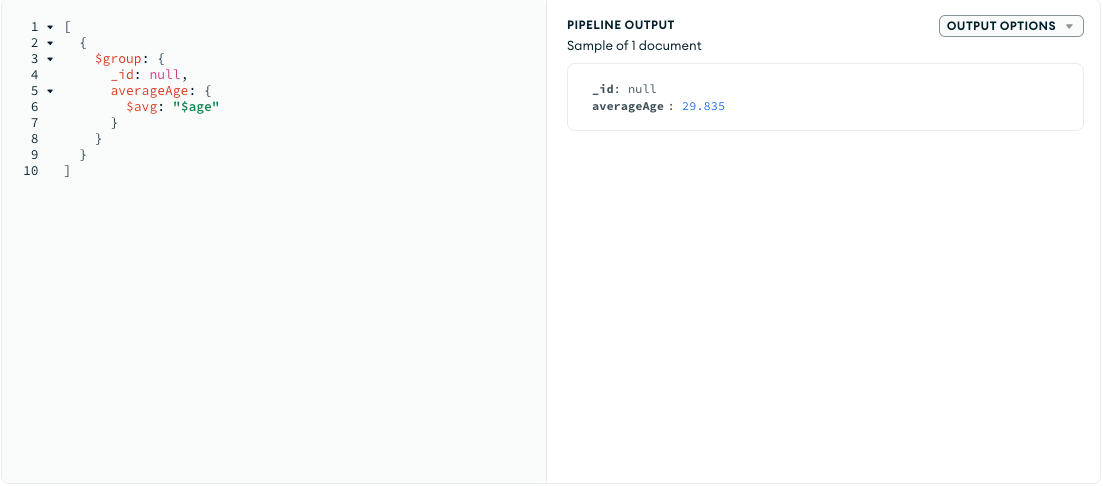
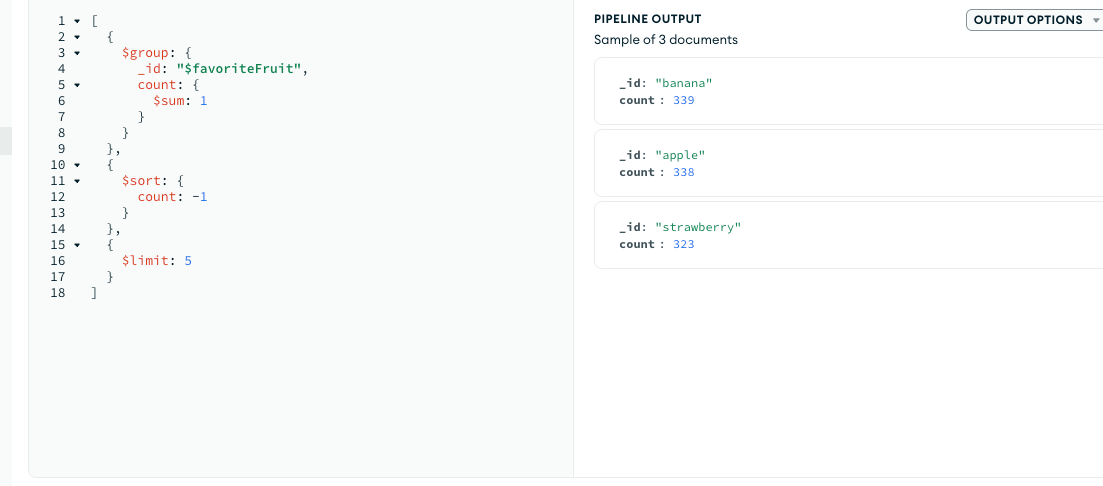
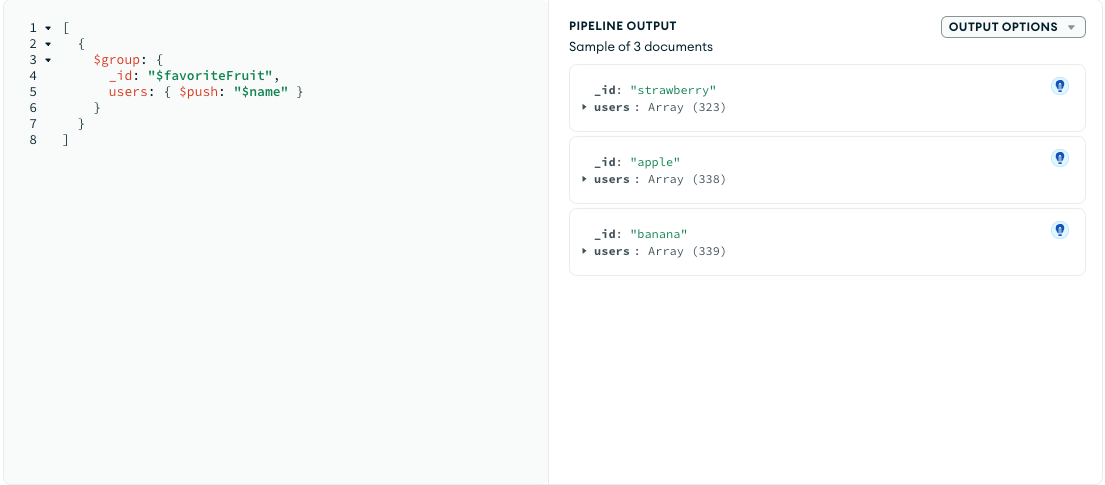
- List the top 5 most common favorite fruits among users
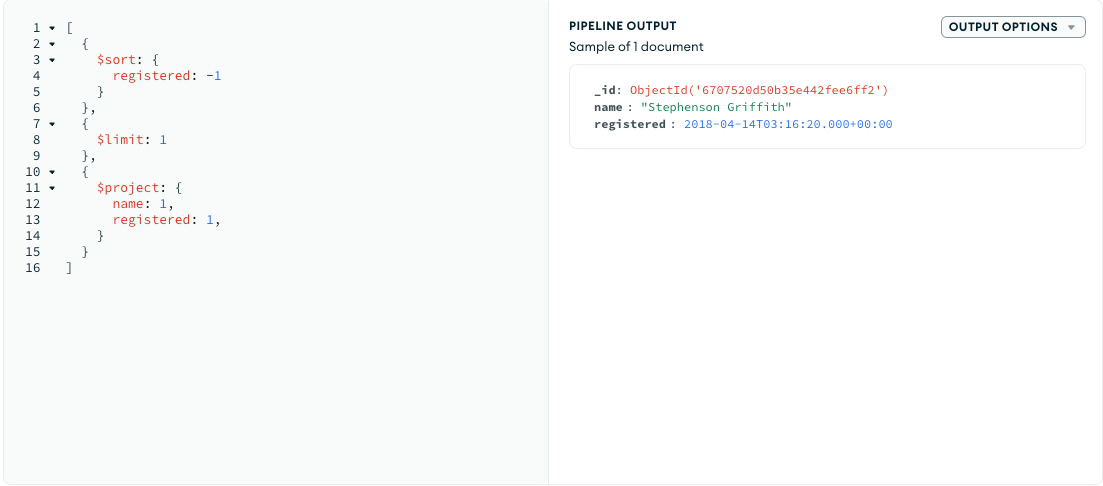
- Who has registered the most recently?
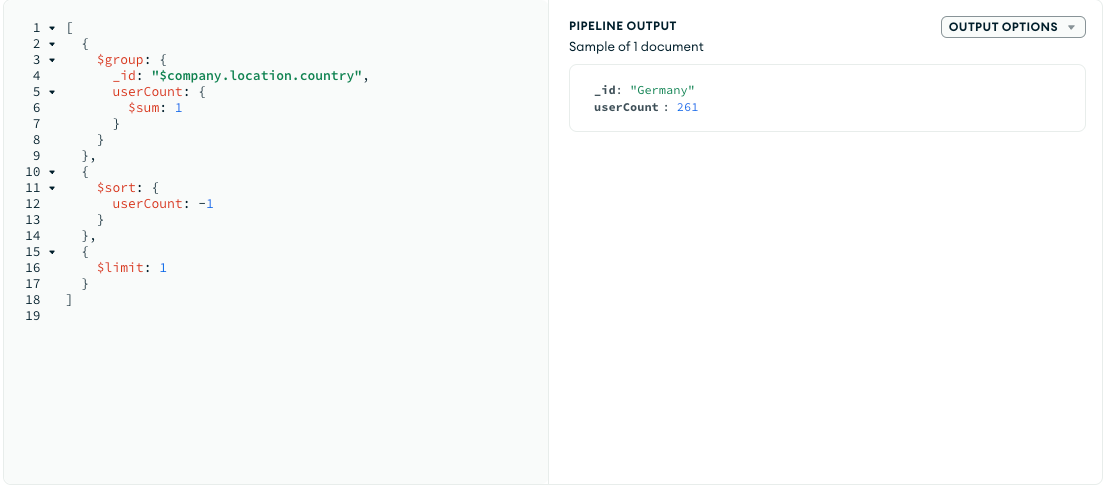
- Which country has the highest number of registered users?
- Categorize users by their favorite fruit
We dissected real-world scenarios, traversing user and book collections, unveiling how aggregation pipelines can breathe life into data relationships. Whether it’s tallying the number of active users, computing averages, or unveiling the most favored fruits, the aggregation pipeline emerges as a versatile artist’s brush, painting a detailed picture of your dataset.
Stay curious, keep coding, and explore the vast possibilities that MongoDB’s Aggregation Pipeline unfolds in your data-driven endeavors
Summary
Aggregation is the process of manipulating large data sets with some specified procedures to return calculated results. These results are provided in a simplified format to enhance the analysis of the associated data.
The aggregation process can be done by either the MapReduce operation or the aggregation pipeline concept in MongoDB. This process is run on the MongoDB instance to simplify the application code, besides the need to limit resource requirements.
The input to an aggregation process is the documents in collections and the result is also a document or several documents.
Aggregation stages involve operators such as addition, averaging values for given fields and finding the maximum and minimum values among many more operators. This analyzes data even more simplified.
Comments ()